機械学習や文字の類似度を求める場合に、自然言語処理をすると思いますが、mecabやsudachiなど様々な自然言語処理を簡単にしてくれるライブラリがあります。その中で精度がよく、継続的に辞書メンテナンスされているsudachiをご紹介いたします。
mecabと比較すると多少処理スピードは落ちますが、辞書地のメンテナンスが継続されていることから精度が高く、windowsでも簡単にPIPでライブラリをインストールできるようになったのもメリットです。
今回はWindowsPCのPython環境で動作するSudachiについてご紹介いたします。
Sudachiをwindows環境にインストールするコマンド
SudachiをwindowsPCにインストールするには下記pipコマンドを利用します。
pip install sudachipypip install sudachidict_corepipでインストルールできない方は会社のproxy環境や証明書の問題が考えられます。Pythonでpip installが使えない時のプロキシとSSL無視にて、対策方法をご紹介しております。
Sudachiの利用方法
Sudachiの分かち書きの粒度は3種類ある
上記方法でSudachiがインストールできたら、下記にてSudachiを読み込みます。Sudachiの大きな特徴として、分かち書きのレベルを選ぶことができます(モードA・B・C)。
- モードCが一番長いワードで分かち書きする
- モードAが一番短いワードで分かち書きする
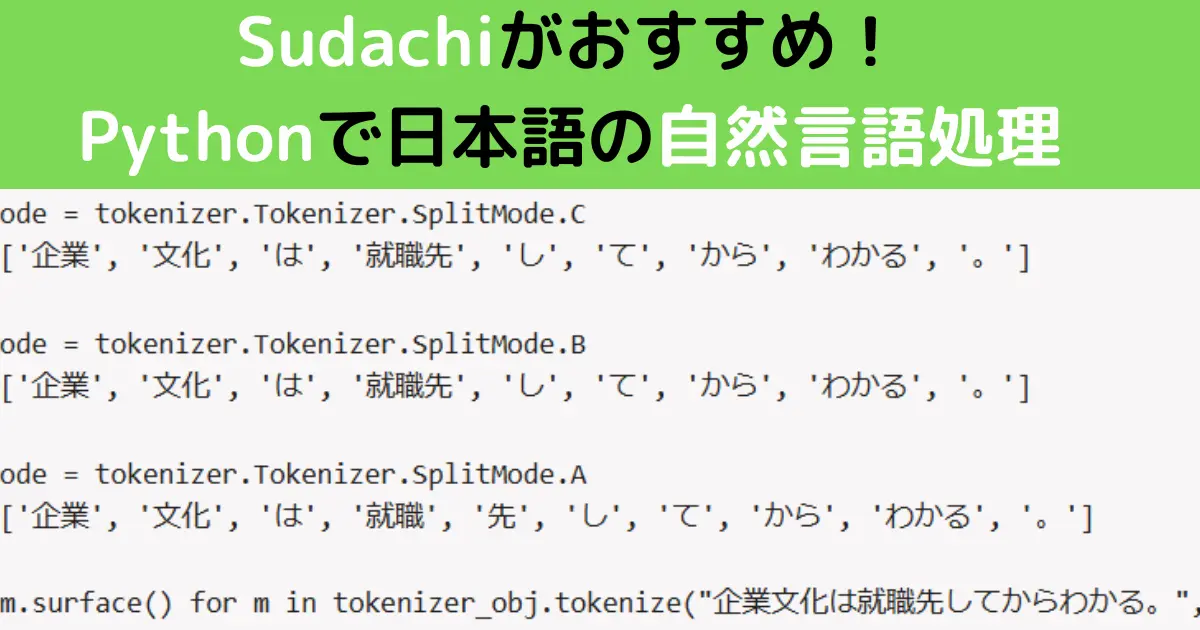
3種類のモードで「企業文化は就職先してからわかる。」の文章を分かち書きした例が下記です。
from sudachipy import tokenizer
from sudachipy import dictionary
tokenizer_obj = dictionary.Dictionary().create()
# 複数粒度分割
mode = tokenizer.Tokenizer.SplitMode.C
#['企業', '文化', 'は', '就職先', 'し', 'て', 'から', 'わかる', '。']
mode = tokenizer.Tokenizer.SplitMode.B
#['企業', '文化', 'は', '就職先', 'し', 'て', 'から', 'わかる', '。']
mode = tokenizer.Tokenizer.SplitMode.A
#['企業', '文化', 'は', '就職', '先', 'し', 'て', 'から', 'わかる', '。']
[m.surface() for m in tokenizer_obj.tokenize("企業文化は就職先してからわかる。", mode)]
どのモードを利用するかは利用用途によりますが、粒度の差でコサイン類似度などの値が変わってきます。
Sudachiの分かち書きでtokenizer.Tokenizer.SplitMode.のABC何を選ぶか
上記例では、動詞など全てのものを含めていますが、本来必要な単位で絞り込み作業を行います。その後にどの粒度のモードを選ぶと精度がよいかを考えると思います。個人的な経験からある程度粒度は大きい方が誤ったものの類似度をあげないので、運用に載せやすい傾向があります。そのため、迷った時はモードCを選ぶことをお勧めいたします。
まとめ
Sudachiを利用して類似度判定するには、それなりのコードを書く必要があります。当サイトの例を1つご紹介すると階層指定クラスタリングのPythonコード紹介と活用例に記事を作成しておりますので、併せて御覧くださいませ。
SudachiのチュートリアルHPを下記にリンクします。