
クラスタリングとは、元データから特定のルールでグループに分類する手段です。階層型クラスタリングとは、最下層のグループとは別に近しいグループで階層があるものです。
Pythonのクラスタリングは機械学習の教師なし学習で、ライブラリのk-meansなどを利用すると簡単に実装できますが、期待した結果にならないことが多いと思います。これは、あくまでも機械的に特徴を判断するため、人間が考える意思決定と特徴が違うのが原因です。
人間の意思を反映して、機械的な分類精度UPを実現する手法が今回ご紹介する私が考える階層指定クラスタリングです。元データから全自動でクラスタリングするのではなく、必ずこのグループに分かれるはず!というカテゴリを見つけて、カテゴリ内でクラスタリングを繰り返していく手法です。
この階層指定クラスタリングを利用することで、分類精度UPが期待でき、自動化率UPにつながります。業務自動化を推進していくうえで重要な考え方になりますので、本記事でご紹介いたします。
階層指定クラスタリングとは?イメージ図で解説
一般的なクラスタリングとは?
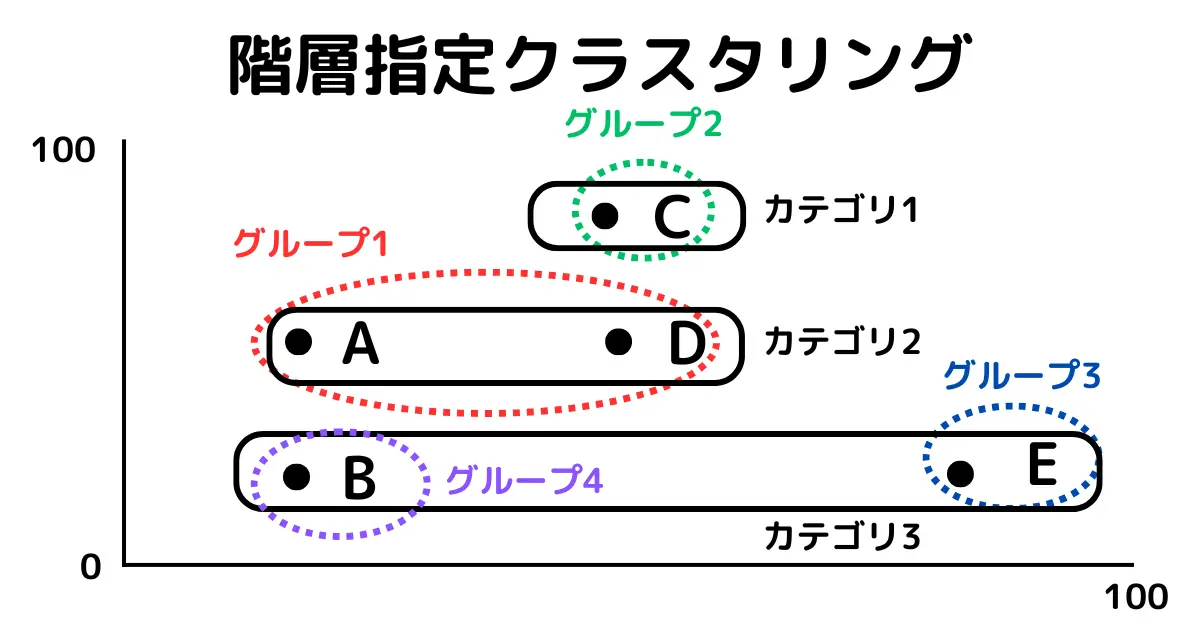
クラスタリングは下図のように機械的に似たグループをいくつかの分類に分ける手段です。

この手法は全範囲を対象としているので「計算量が多い」と「精度が低い」傾向があります。上図でグループ1でAとBが同じグループに分類されたが、実はAとDが同じグループだったというケースがあります。この問題の解決策が次章で解説する階層指定クラスタリングになります。
階層指定クラスタリングとは?
階層指定クラスタリングは、事前にこのグループ(カテゴリなど)の中でしか、絶対グループされない!という分類をみつけだし、その中でクラスタリングする手法です。下図は、カテゴリ1~3の中でクラスタリングするイメージを作成しました。
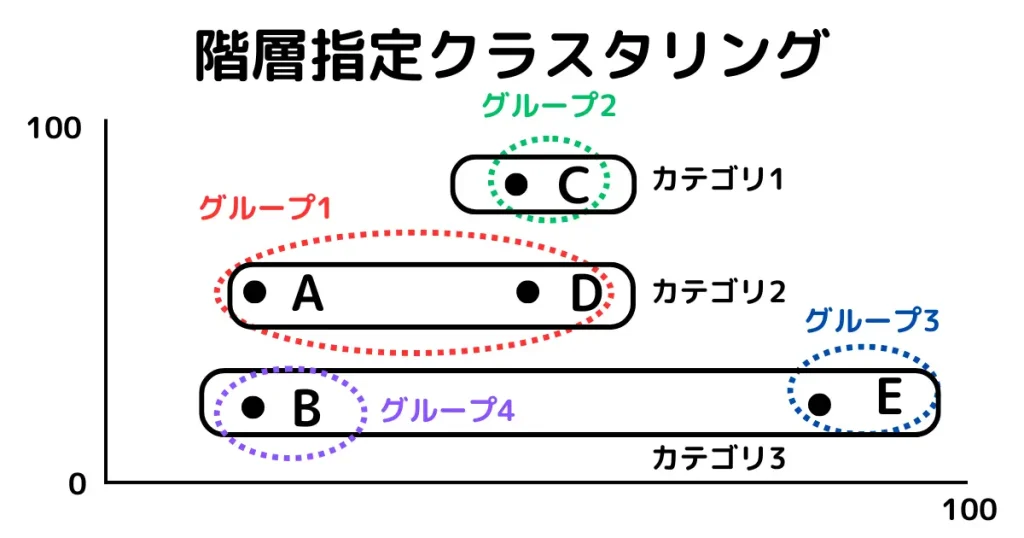
カテゴリの中でクラスタリングするので、全データを比較する必要がないので計算量が少ないです。更に、本来異なるグループが同一グループに分類されることを防ぐ効果があります。
Pythonで階層指定クラスタリングを行う方法
クラスタリングに使うサンプルファイルを読み込む
下記データを例にクラスタリングコードをご紹介いたします。
■商品情報ファイル1
| カテゴリ | 商品名 | 原価 | 個数 | 在庫金額 | 販売開始日 | 販売終了日 |
|---|---|---|---|---|---|---|
| 1 | カビキラー | 1158 | 1 | 1158 | 2025/01/20 | 2025/03/20 |
上記ファイルをPandasで読み込むコードは下記。
import pandas as pd
input_file_ = ファイルpathを指定
shohin_data_=pd.read_csv(input_file_)同一グループに属するKeyを見つける。本記事では「カテゴリーID」をkeyとする
全データから、対象範囲を絞れるkeyとなるものがないか探します。今回のデータは商品情報が大きな分類であるカテゴリ毎に分かれていますので、「カテゴリーID」をグループ単位のkeyとして、その中でクラスタリングするかたちで進めます。
カテゴリIDをkeyとしてループ処理する方法の1つとして、1つのデータを2つに分解して回す手法を次章で解説致します。
同一グループ内とするKeyのデータを作成する
「カテゴリID」をkeyとしてロープ処理するために、keyとなるカテゴリIDが重複しないように.drop_duplicates()を用いて重複データを削除し、ユニークなkeyデータを作成します。
#Keyを決めるデータを作成する カテゴリIDをkeyとして設定する
key_=shohin_data_[["カテゴリーID"]].drop_duplicates()上記のユニークなカテゴリIDにたいして、連番を振ります。PandasのDataFrameでループ文をまわすのは直感的にわかりずらいので、下記のようにリスト型に変換しておきます。
#key連番を振る
key_list_=[(no,i[0]) for no,i in enumerate(key_.values.tolist())]
key_df_=pd.DataFrame(key_list_,columns=["key","カテゴリーID"])
#結果
#key_list_の値は[(0, 1), (1, 9)]のようになります。これをDF化Pandasのdf..values.tolist()を使えばDataFrameからlist型に変更することができます。クラスタリングのループ処理ではkeyとなるデータに連番を付けて処理する流れが管理上楽で誤りを防止できます。
連番を付与したので、上記結果のように0,1のように連番が追加されました。この連番をもう1つの商品情報の方にも反映させます。
2重ループを回すために外側ループデータを作成する
2重ループする時に、対象範囲を指定する外側ループ用データを作成します。今回はユニークになるものを商品名として、keyとなるカテゴリIDとセットのデータを作成します。
#ループ外側のデータ作成
categoly_=shohin_data_[["カテゴリーID","商品名"]].drop_duplicates()2重ループする両方のデータにkeyを反映し、昇順に並び変える
2重ループするために、外側ループ用と内側ループ用の両データにkeyを反映します。
#Keyを両テーブルに反映させて、key順番に揃える
#①カテゴリ情報(外側ループ)
categoly_df_=pd.merge(key_df_,categoly_,on="カテゴリーID",how="right")
categoly_df_ = categoly_df_.sort_values(['key'])
#②商品情報(内側ループ)
shohin_data_df_=pd.merge(key_df_,shohin_data_,on="カテゴリーID",how="right")
shohin_data_df_ = shohin_data_df_.sort_values(['key'])
ロープ処理する時にkeyの番号が変わったらconinueやbreakするので、keyの順番を両方とも昇順にあわせておきます。
階層指定でループ文を回すPython関数
外側ループ用のデータをlist1,内側ループ用のデータをlist2とします。これらは上記で作成したDataframeをforループ用に.values.tolist()を用いてlist化したものです。Similarity_xは類似度判定するpython関数を想定しております。Similarity_xはテキスト類似度で求める場合と画像類似度で求める場合があります。両ケースは別記事にてご紹介いたします。尚、本記事では商品名を類似度判定として利用しています。
画像類似度の判定方法についてはPythonの画像類似度判定で同一画像や近い画像を検知するの記事をご覧くださいませ。
外側ループでlist1のkeyがno1~開始され、key単位で商品名の類似度を比較を繰り返します。類似度は0~1の範囲で判定されるので、ここでは0.4以上の類似度であれば同じグループ(クラスタ)とします。
#関数
def cluster(list1,list2,Similarity_x):
#クラスタ番号
group_no_ = 0
#商品単位のユニークkey ※今回は商品名
match_words_ ={}
match_words_ = set(match_words_)
#閾値
score = 0.4
#保管リスト
rezult_lists =[]
#カテゴリIDデータ
for i1 in list1:
#0:Key
#1:カテゴリID
#2:商品名
#グループ番号発行
group_no_ += 1
#商品データ
for i2 in list2:
#0:key
#1:カテゴリID
#2:商品名
#3以降省略
#条件判断① 同じkey以外はスキップする処理
if i1[0] > i2[0]:
continue
elif i1[0] < i2[0]:
break
#keyが同一の場合のみロジック実行
else:
#ロジック実行
#match_words_にここでは商品名が入っていないものを対象とする
if i2[2] not in match_words_:
#グループ番号発行
#group_no_ += 1
#ワードの有無
if i2[2] not in match_words_:
#類似度処理
Similarity_y
#類似度が閾値以上のものはグループとして登録する
if Similarity_y >= score:
group_no_ = group_no_
match_words_.add(i2[2])
else:
continue
rezult_lists.append((group_no_,i2[2],Similarity_y))
rezultdf_ = pd.DataFrame(rezult_lists,columns=["グループNo","商品名","類似度"])
return rezultdf_
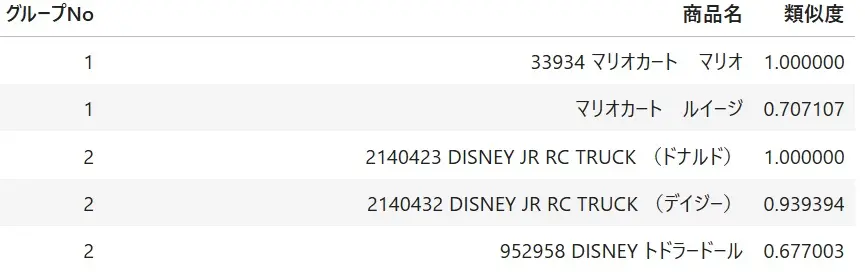
上記ロジックで実施した結果は下記です。商品名の類似度が0.4以上を対象に同じグループNOになっています。
まとめ
今回ご紹介した階層型クラスタリングは大量データを機械的にグループ化することができます。100%の精度を求めるのは厳しい一方、工夫して運用に組み込むことができれば大きな成果が期待できる技術です。この方法で10年かかる作業が1日で終わる。そんなインパクトを持っています。
技術フォローやコンサル依頼はお問い合わせ・ご依頼にて受け付けております。







