Pandasのピボットテーブルなどのデータ加工をするとマルチインデックス(マルチカラム)になる時があります。データ加工難易度を下げるために、マルチインデックスを解除しデータを連結しながら進めていくことが多いと思います。
本記事では、意図せずマルチインデックス化されてしまったPandasのDataframeにおいて、マルチインデックスを解除する方法をご紹介いたします。
Pandaインデックスをリセットする方法
必用ライブラリ
import pandas as pdSamleファイルの読み込み
約2,000件のサンプルファイルを読み込みます。
input_csv=r"C:\Users\abi00\デスクトップ\商品情報2000件.csv"
df1=pd.read_csv(input_csv)
df1dfの結果は下記
インデックスを解除する(reset_index)
Pandasのピボットテーブル機能を利用して、データ階層を変えて表示します。その後、階層を合わせるためにインデックスを振りなおす処理をご紹介します。
df2=df1.pivot_table(index="カテゴリーID",values="在庫金額",aggfunc="sum")
df2df2の結果を見ると「カテゴリID」と「在庫金額」の階層が違うことがわかります。階層レベルを合わせるにはインデックスをリセットして振りなおす必要があります(下記)
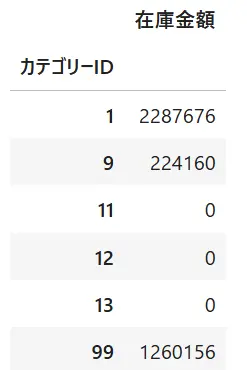
Pandasでインデックスを解除するにはreset_index()を使い、インデックスを振りなおすことで項目名の行にカテゴリIDと在庫金額を並べることができます。
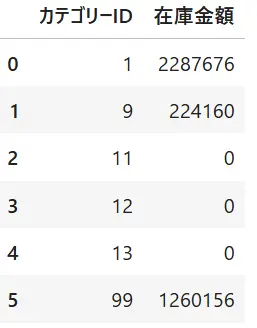
df2.reset_index()reset_index()を行ったことで、「カテゴリーID」と「在庫金額」が同じ階層(項目名)として表示されました。
データが整備されたことでこの後のデータ加工がしやすくなります。
Pandasでマルチインデックスを解除する方法
マルチインデックスのデータを作成します。(下記)
df3=df1.pivot_table(index=["カテゴリーID","原価","在庫金額"],values="個数",aggfunc="count")
df3df3のデータを表示します。インデックスには「”カテゴリーID”,”原価”,”在庫金額”」の順番に並んでいます。
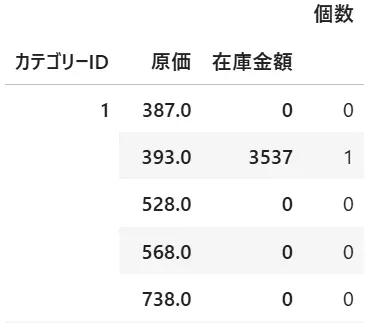
マルチインデックスを解除するにはdf.index=df.index.droplevel(0)を利用します。()内の数値はレベルを示しており、数値を変えることで、どのインデックスを削除するか指定することができます。下記で0,1を削除した例を示します。
df3.index=df3.index.droplevel(0)
df3
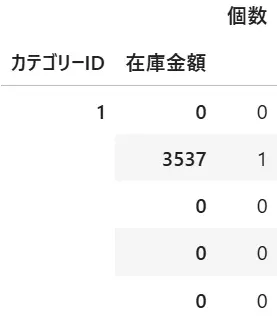
df3.index=df3.index.droplevel(1)
df3df3.index.droplevel(0)
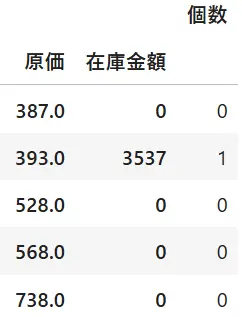
df3.index.droplevel(1)
Pandasでマルチカラムを解除する方法
ピボットテーブルで値などを複数選択するとマルチインデックスになります。
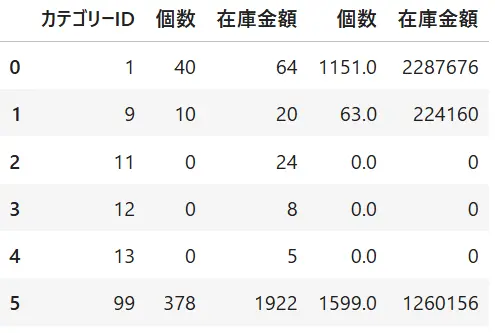
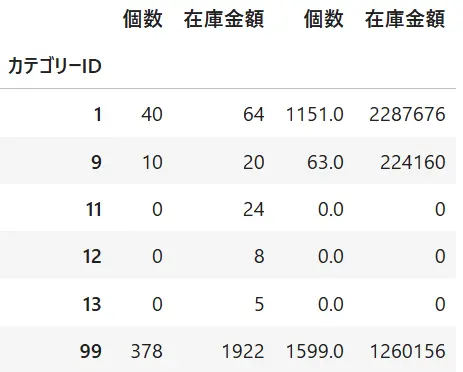
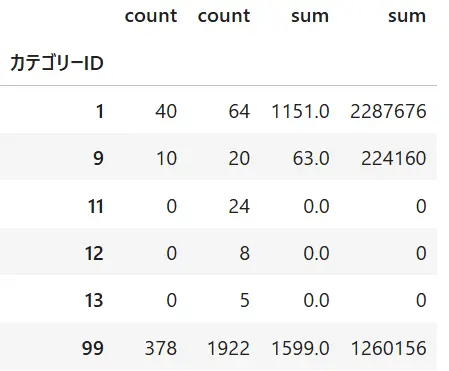
df2=df1.pivot_table(index="カテゴリーID",values=["個数","在庫金額"],aggfunc=["count","sum"])項目を見るとcount,sumと個数、在庫の項目が階層違いであることがわかります。
このDataを個数、在庫金額に統一する方法をご紹介します。
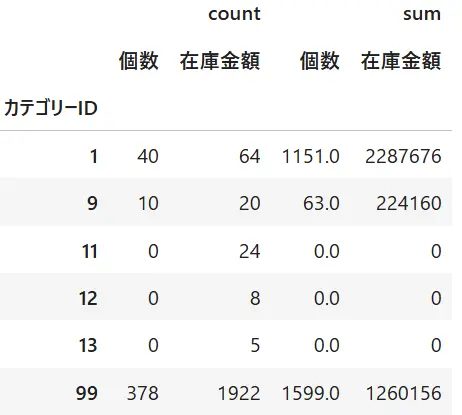
Pandasでマルチカラムを削除するにはcolumns.droplevel()を利用します。()内には削除するカラムレベルを設定します。下記例では0と1を入れて結果を並べてみました(下図)
#レベル0のカラム削除
df2.columns=df2.columns.droplevel(0)
#レベル1のカラム削除
df2.columns=df2.columns.droplevel(1)
df.columns.droplevel(0)
df.columns.droplevel(1)
df2.columns.droplevel(0)でマルチカラムを解除したデータにたいして、インデックスをリセットした例が下記です。
カテゴリId~在庫金額までが項目名として1行に並びました。個数、在庫金額に関しては名称が重複すうのでリネームで好きな名前に変換すればよいでしょう。